干貨 日處理20億數據,攜程實時用戶行為服務系統架構實踐
在數字化時代,用戶行為數據是企業洞察市場、優化產品、提升用戶體驗的核心資產。作為全球領先的在線旅游服務平臺,攜程每天需要處理高達20億條用戶行為數據,這對實時數據處理服務系統提出了極高的要求。本文將深入解析攜程在構建高并發、低延遲、高可用的實時用戶行為服務系統方面的架構實踐與核心經驗。
一、業務挑戰與技術目標
面對海量、高并發的用戶行為數據,攜程的系統需要解決以下核心挑戰:數據采集的實時性與完整性、數據處理的低延遲與高吞吐、系統的高可用與可擴展性。為此,技術團隊設定了明確目標:實現秒級甚至毫秒級的數據采集與處理延遲,保證99.99%的系統可用性,并具備彈性伸縮能力以應對流量峰值。
二、整體架構設計
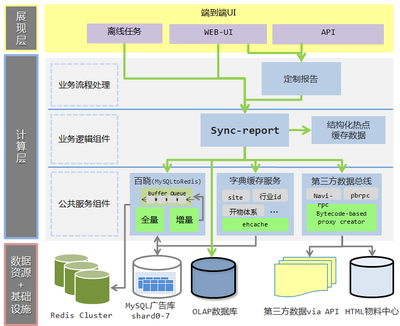
攜程的實時用戶行為服務系統采用分層、解耦的微服務架構,主要分為數據采集層、消息隊列層、流處理層、存儲層與應用服務層。
- 數據采集層:客戶端(Web、App、小程序等)通過輕量級SDK,將用戶點擊、瀏覽、搜索等行為日志進行標準化封裝,并采用異步、批量上報策略,結合本地緩存與重試機制,確保數據不丟失且減少網絡開銷。服務端接收服務采用高并發設計,通過負載均衡將請求分發至多個采集節點。
- 消息隊列層:采集到的原始數據首先寫入高性能消息隊列(如Kafka),作為整個系統的數據總線。Kafka的高吞吐和持久化特性,實現了生產與消費的解耦,并為數據提供了緩沖能力,有效應對流量尖峰。
- 流處理層:這是系統的核心。攜程采用了Flink作為流計算引擎。Flink的Exactly-Once語義保證了數據處理的準確性,其低延遲和高吞吐的特性非常適合實時分析場景。在這一層,系統對原始行為數據進行清洗、過濾、格式化、聚合(如計算實時PV/UV、會話分析)、以及實時特征提取,為后續的實時推薦、風控、儀表盤等應用提供直接可用的數據。
- 存儲層:根據數據的使用場景,采用多元化的存儲方案:
- 實時聚合結果和用戶畫像特征:存入高性能的KV存儲(如Redis)或內存數據庫,供在線服務毫秒級查詢。
- 明細數據與中間狀態:存入分布式列式存儲(如HBase)或云原生數據倉庫,支持即席查詢與歷史回溯。
- 長期歸檔與離線分析:定期同步至HDFS或數據湖(如Iceberg),構建離線數倉。
- 應用服務層:基于處理后的實時數據,構建了一系列服務,如實時個性化推薦、實時風控預警、實時運營儀表盤、A/B測試平臺等。這些服務通過統一的API網關對外提供低延遲的數據查詢與訂閱服務。
三、核心技術實踐與優化
- 資源彈性與調度:系統部署在容器化云平臺上,利用Kubernetes實現計算資源的彈性伸縮。流處理任務可以根據數據吞吐量動態調整并發度,實現成本與效率的最優平衡。
- 數據質量與監控:建立了端到端的數據鏈路監控體系,跟蹤從數據產生、傳輸、處理到消費的全鏈路延遲與完整性。通過監控大盤和實時告警,快速定位故障。通過數據血緣追蹤和一致性校驗,保障數據質量。
- 容錯與高可用:關鍵組件均采用多副本、跨可用區部署。Flink作業定期進行Checkpoint,確保故障時能快速從狀態恢復。存儲層實現多活或主從熱備,確保服務不間斷。
- 性能優化:在網絡層面,優化序列化協議(如使用Protobuf);在計算層面,對Flink作業進行細粒度調優,包括合理設置時間窗口、利用狀態后端優化、使用旁路輸出處理復雜邏輯等。
四、與展望
攜程的實時用戶行為服務系統通過分層的架構設計、強大的流處理引擎和多元化的存儲選型,成功支撐了日均20億數據量的實時處理需求,為業務提供了強大的數據驅動能力。隨著數據規模的持續增長和業務場景的日益復雜,系統將繼續向更智能化(如實時機器學習平臺集成)、更云原生、以及批流一體融合的方向演進,以更高效、更靈活地挖掘用戶行為數據的無限價值。
此架構實踐不僅適用于在線旅游行業,也為電商、社交、內容平臺等任何需要處理海量實時用戶行為數據的公司提供了寶貴的參考范式。
如若轉載,請注明出處:http://www.100lishi.cn/product/66.html
更新時間:2026-04-18 20:38:57