從Greenplum、Hadoop到阿里大數(shù)據(jù)技術(shù) 數(shù)據(jù)處理服務(wù)的演進之路
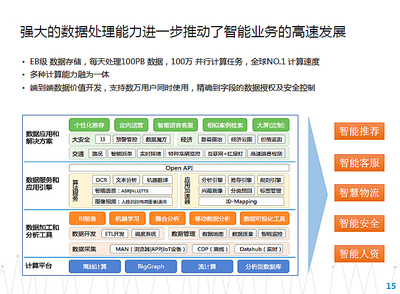
大數(shù)據(jù)時代,數(shù)據(jù)處理技術(shù)的發(fā)展經(jīng)歷了從傳統(tǒng)數(shù)據(jù)倉庫到分布式計算,再到云原生智能化的深刻變革。這一演進路徑,清晰地體現(xiàn)在從Greenplum、Hadoop到如今以阿里云為代表的新一代大數(shù)據(jù)技術(shù)體系的變遷中。它們不僅是技術(shù)的迭代,更是數(shù)據(jù)處理服務(wù)理念從工具到平臺、再到全棧服務(wù)化解決方案的升華。
1. 傳統(tǒng)MPP架構(gòu)的奠基:Greenplum的時代
在早期大數(shù)據(jù)探索階段,Greenplum作為基于開源PostgreSQL的MPP(大規(guī)模并行處理)數(shù)據(jù)庫,扮演了重要角色。它通過將數(shù)據(jù)分布到多個節(jié)點并行處理,有效提升了海量數(shù)據(jù)分析的性能。Greenplum的核心優(yōu)勢在于其對標(biāo)準SQL的良好支持和對傳統(tǒng)數(shù)據(jù)倉庫工作負載的繼承,使得企業(yè)能夠相對平滑地從傳統(tǒng)架構(gòu)過渡到初步的“大數(shù)據(jù)”分析。它代表了以結(jié)構(gòu)化數(shù)據(jù)為中心、強一致性的數(shù)據(jù)處理范式,為后續(xù)技術(shù)發(fā)展奠定了并行計算和分布式存儲的思想基礎(chǔ)。其擴展性、對非結(jié)構(gòu)化數(shù)據(jù)的處理能力以及對實時流計算支持的局限,也催生了下一階段的革命。
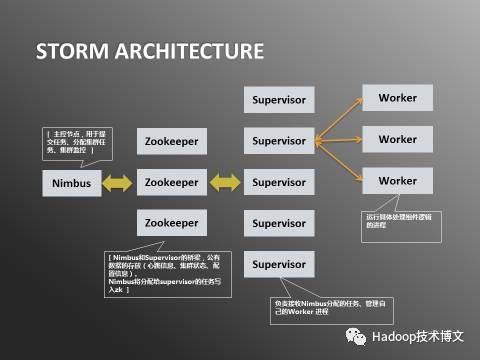
2. 開源生態(tài)的爆發(fā)與局限:Hadoop的統(tǒng)治與挑戰(zhàn)
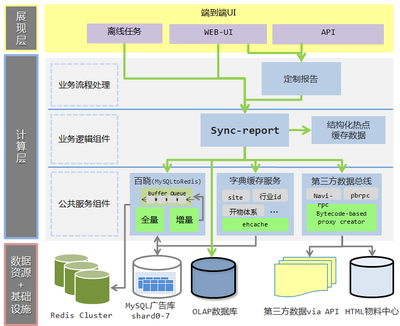
Apache Hadoop的興起,標(biāo)志著大數(shù)據(jù)進入開源生態(tài)驅(qū)動的規(guī)模化時代。其核心HDFS(分布式文件系統(tǒng))提供了近乎無限的存儲擴展能力,而MapReduce編程模型則定義了批處理的計算范式。圍繞Hadoop形成的龐大生態(tài)(如Hive、HBase、Spark等)解決了Greenplum時代在成本、非結(jié)構(gòu)化數(shù)據(jù)處理和極致擴展性方面的諸多問題。Hadoop將“數(shù)據(jù)湖”的概念推向主流,允許以原始格式存儲各類數(shù)據(jù),按需計算。其復(fù)雜性也日益凸顯:運維門檻高、實時性弱(原生MapReduce)、多組件集成繁瑣,使得“擁有數(shù)據(jù)”和“高效使用數(shù)據(jù)”之間產(chǎn)生了巨大鴻溝。數(shù)據(jù)處理依然是一項需要深厚專業(yè)知識的“重型”工程。
3. 云原生與智能化的融合:阿里大數(shù)據(jù)技術(shù)的躍遷
當(dāng)前,以阿里云MaxCompute、Flink、PolarDB等為代表的大數(shù)據(jù)技術(shù),代表了數(shù)據(jù)處理服務(wù)的第三階段——云原生、全棧化、智能化與實時化。這一階段的技術(shù)演進并非簡單替代Hadoop,而是在理念上實現(xiàn)了跨越:
- 服務(wù)化與普惠化:如MaxCompute,提供了完全托管、免運維的大數(shù)據(jù)計算服務(wù)。用戶無需關(guān)心底層集群,按需付費,極大地降低了使用門檻,使數(shù)據(jù)處理能力成為像水電一樣可輕松獲取的基礎(chǔ)服務(wù)。
- 流批一體與實時化:以Apache Flink(阿里為重要貢獻者)為核心的實時計算技術(shù),統(tǒng)一了流處理和批處理,使得“實時洞察”和“離線分析”的邊界模糊,滿足了數(shù)字化業(yè)務(wù)對實時性的苛刻要求。
- 智能融合與一體化:大數(shù)據(jù)與AI平臺(如阿里云PAI)深度集成,數(shù)據(jù)處理管道能無縫對接模型訓(xùn)練與推理,實現(xiàn)了從數(shù)據(jù)到智能的閉環(huán)。湖倉一體架構(gòu)(如結(jié)合OSS與MaxCompute)融合了數(shù)據(jù)湖的靈活性與數(shù)據(jù)倉庫的治理性能。
- 云原生與極致彈性:全面基于容器、Kubernetes等云原生技術(shù),計算與存儲分離,實現(xiàn)秒級彈性伸縮,資源利用率與成本效益遠勝傳統(tǒng)固定集群。
結(jié)論:從工具到服務(wù),從數(shù)據(jù)到價值
從Greenplum的并行化啟蒙,到Hadoop的生態(tài)化擴張,再到阿里大數(shù)據(jù)技術(shù)的云原生智能化,其主線是讓數(shù)據(jù)處理從專家手中的復(fù)雜工具,轉(zhuǎn)變?yōu)橘x能全社會的便捷服務(wù)。未來的數(shù)據(jù)處理服務(wù),將更加聚焦于隱藏技術(shù)復(fù)雜性,提供開箱即用的、融合了實時分析、AI挖掘與完善治理能力的統(tǒng)一平臺。技術(shù)演進的目標(biāo)始終如一:縮短從原始數(shù)據(jù)到業(yè)務(wù)價值的距離,讓數(shù)據(jù)真正成為驅(qū)動創(chuàng)新的核心生產(chǎn)要素。
如若轉(zhuǎn)載,請注明出處:http://www.100lishi.cn/product/62.html
更新時間:2026-04-16 19:35:04